Publications
Here you'll find my research papers ...
2026
- CoRR-2026
 Mehrdad Farahani , Franziska Penzkofer , and Richard Johansson2026
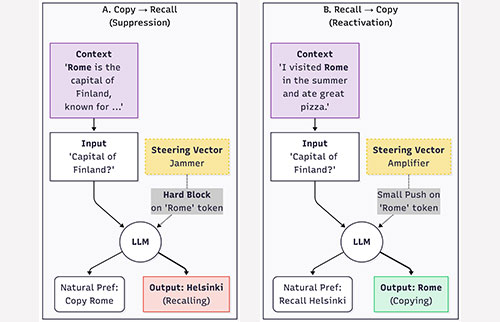
Mehrdad Farahani , Franziska Penzkofer , and Richard Johansson2026Language models used in retrieval-augmented settings must arbitrate between parametric knowledge stored in their weights and contextual information in the prompt. This work presents a mechanistic study of that choice by extracting an \empharbitration vector from model activations on a curated dataset designed to disentangle (i) irrelevant contexts that elicit parametric recall and (ii) relevant but false contexts that elicit copying. The vector is computed as the residual-stream centroid difference between these regimes across 27 relations, and is injected as an additive intervention at selected layers and token spans to steer behavior in two directions: Copy→Recall (suppressing context use) and Recall→Copy (inducing the model to copy any token from the context). Experiments on two architectures (decoder-only and encoder/decoder) and two open-domain QA benchmarks show consistent behavior shifts under moderate scaling while monitoring accuracy and fluency. Mechanistic analyses of attention routing, MLP contributions, and layer-wise probability trajectories reveal an asymmetry: inducing copying is an easy “reactivation” process that can be triggered at different locations in the input, while restoring recall is a “suppression” process that is more fragile and strongly tied to object-token interventions.
@misc{farahani-penzkofer-johansson-2026-copy, title = {To Copy or Not to Copy: Copying Is Easier to Induce Than Recall}, author = {Farahani, Mehrdad and Penzkofer, Franziska and Johansson, Richard}, year = {2026}, url = {https://arxiv.org/abs/2601.12075}, eprint = {2601.12075}, archiveprefix = {arXiv}, primaryclass = {cs.CL}, }
2024
- Mehrdad Farahani and Richard JohanssonIn Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, Nov 2024
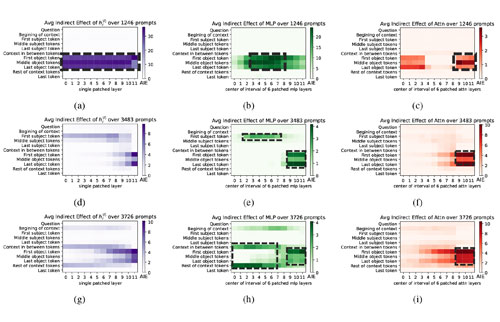
Generative language models often struggle with specialized or less-discussed knowledge. A potential solution is found in Retrieval-Augmented Generation (RAG) models which act like retrieving information before generating responses. In this study, we explore how the Atlas approach, a RAG model, decides between what it already knows (parametric) and what it retrieves (non-parametric). We use causal mediation analysis and controlled experiments to examine how internal representations influence information processing. Our findings disentangle the effects of parametric knowledge and the retrieved context. They indicate that in cases where the model can choose between both types of information (parametric and non-parametric), it relies more on the context than the parametric knowledge. Furthermore, the analysis investigates the computations involved in \textithow the model uses the information from the context. We find that multiple mechanisms are active within the model and can be detected with mediation analysis: first, the decision of \textitwhether the context is relevant, and second, how the encoder computes output representations to support copying when relevant.
@inproceedings{farahani-johansson-2024-deciphering, title = {Deciphering the Interplay of Parametric and Non-parametric Memory in Retrieval-augmented Language Models}, author = {Farahani, Mehrdad and Johansson, Richard}, year = {2024}, month = nov, booktitle = {Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing}, publisher = {Association for Computational Linguistics}, address = {Miami, Florida, USA}, pages = {16966--16977}, doi = {10.18653/v1/2024.emnlp-main.943}, url = {https://aclanthology.org/2024.emnlp-main.943/}, editor = {Al-Onaizan, Yaser and Bansal, Mohit and Chen, Yun-Nung}, }
2023
- Mehrdad Farahani and Richard JohanssonIn Proceedings of the 24th Nordic Conference on Computational Linguistics (NoDaLiDa), May 2023
Autoregressive models used to generate responses in open-domain dialogue systems often struggle to take long-term context into account and to maintain consistency over a dialogue. Previous research in open-domain dialogue generation has shown that the use of \textitauxiliary tasks can introduce inductive biases that encourage the model to improve these qualities. However, most previous research has focused on encoder-only or encoder/decoder models, while the use of auxiliary tasks in \textitencoder-only autoregressive models is under-explored. This paper describes an investigation where four different auxiliary tasks are added to small and medium-sized GPT-2 models fine-tuned on the PersonaChat and DailyDialog datasets. The results show that the introduction of the new auxiliary tasks leads to small but consistent improvement in evaluations of the investigated models.
@inproceedings{farahani-johansson-2023-empirical, title = {An Empirical Study of Multitask Learning to Improve Open Domain Dialogue Systems}, author = {Farahani, Mehrdad and Johansson, Richard}, year = {2023}, month = may, booktitle = {Proceedings of the 24th Nordic Conference on Computational Linguistics (NoDaLiDa)}, publisher = {University of Tartu Library}, address = {T{\'o}rshavn, Faroe Islands}, pages = {347--357}, url = {https://aclanthology.org/2023.nodalida-1.36/}, editor = {Alum{\"a}e, Tanel and Fishel, Mark}, }
2021
- Mehrdad Farahani , Mohammad Gharachorloo , and Mohammad ManthouriIn 2021 26th International Computer Conference, Computer Society of Iran (CSICC), May 2021
@inproceedings{pnSummary, title = {Leveraging ParsBERT and Pretrained mT5 for Persian Abstractive Text Summarization}, author = {Farahani, Mehrdad and Gharachorloo, Mohammad and Manthouri, Mohammad}, year = {2021}, booktitle = {2021 26th International Computer Conference, Computer Society of Iran (CSICC)}, volume = {}, number = {}, pages = {1--6}, doi = {10.1109/CSICC52343.2021.9420563}, url = {https://ieeexplore.ieee.org/document/9420563}, keywords = {Computational modeling;Bit error rate;Natural language processing;Task analysis;Text Summarization;Abstractive Summarization;BERT;BERT2BERT;mT5;Pars-BERT}, } - Mehrdad Farahani , Mohammad Gharachorloo , Marzieh Farahani , and Mohammad ManthouriNeural Processing Letters, May 2021
@article{parsBERT, title = {Parsbert: Transformer-based model for persian language understanding}, author = {Farahani, Mehrdad and Gharachorloo, Mohammad and Farahani, Marzieh and Manthouri, Mohammad}, year = {2021}, journal = {Neural Processing Letters}, publisher = {Springer}, volume = {53}, number = {6}, pages = {3831--3847}, url = {https://link.springer.com/article/10.1007/s11063-021-10528-4}, }